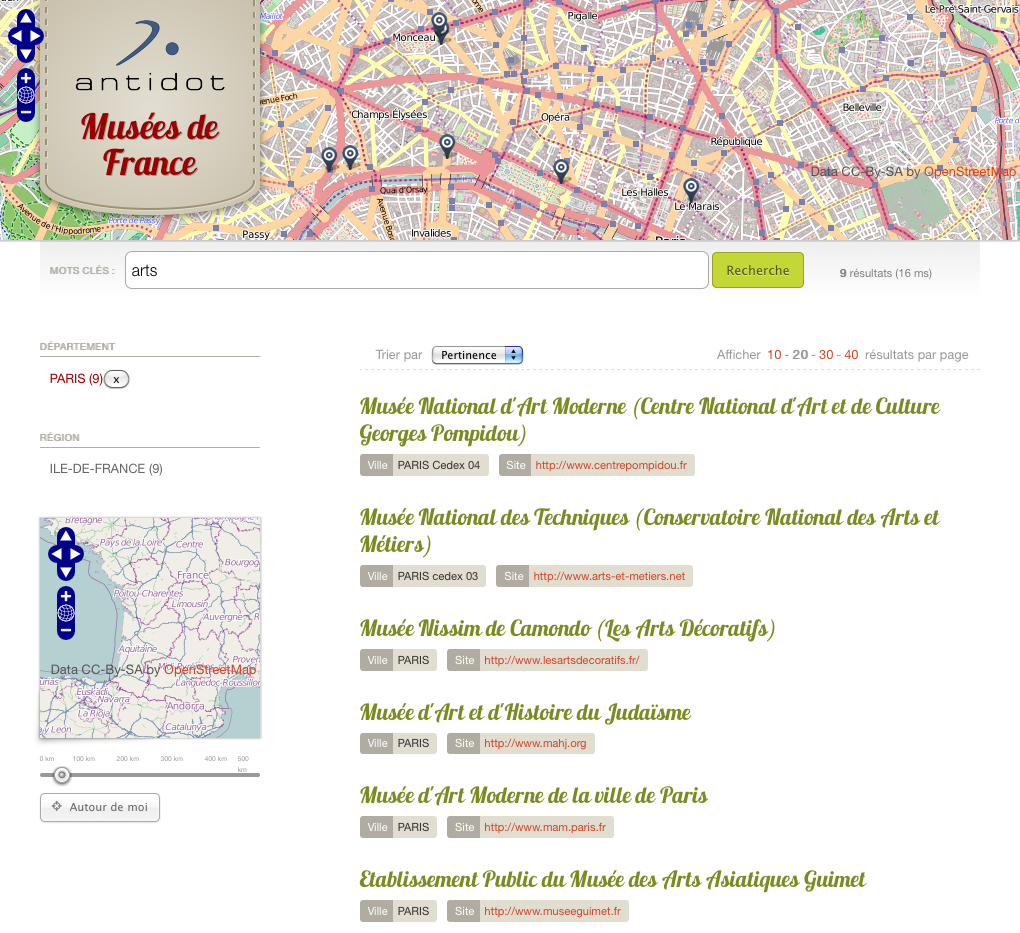
Nous avons vu précédemment qu’avec la version 7.6 de nos outils, la création de chaînes de traitement de données était extrêmement simple : il est possible de réaliser une application web de recherche de musées en quelques minutes. Pour autant, nos clients utilisent Antidot Information Factory dans des projets où les chaines de traitement sont plus beaucoup plus complexes.
Afin de montrer comment AIF répond aussi à des besoins plus avancés, nous allons donc améliorer notre application « Musées de France » en enrichissant les données initiales. Nous avons retenu trois enrichissements :
- trouver des photos sur un site de photos en ligne (Flickr ou Wikimedia par exemple)
- trouver les gares SNCF les plus proches de chaque musée
- ajouter un contenu textuel présentant chaque musée
Des photos !
Le premier enrichissement a pour objectif de montrer qu’AIF est très à l’aise avec des données multimédia. Nous y introduirons également l’organisation des données dans chaque « objet document », que nous avions passée sous silence dans le précédent billet.
Flickr.com possède des API accessibles en web services, tout comme Google Maps. En utilisant le même module d’interrogation d’un web service, nous allons obtenir une liste de photos associées à chaque musée. Nous utiliserons ensuite un module de téléchargement qui récupérera les 3 premières photos renvoyées par Flickr.
N.B. : Les photos renvoyées par Flickr ne sont pas forcément des photos du musée en question, il peut s’agir de photos prises à proximité du musée. Nous accepterons cette simplification pour l’exemple.
Organisons nos données
Vous vous souvenez que notre base de données des musées de France était, à l’origine, un tableau Excel. Comment associe-t-on des photos à une ligne Excel ?
C’est ce que nous allons faire facilement, car Information Factory se fonde sur un modèle de données riche et organisé. Chaque ressource manipulée – ici une ligne Excel désignant un musée de France – est une mini base de données. Avec AIF, nous allons ranger les informations manipulées dans des couches de données bien identifiées, chaque couche ayant un rôle bien défini.
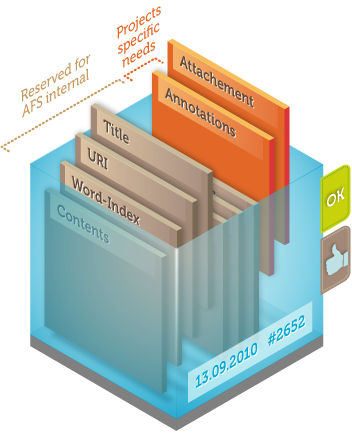
La couche principale se nomme « Contents » et elle contient la transformation XML de la ligne Excel décrivant le musée.

Certaines couches ont des libellés spécifiques car elles sont destinées à des usages particuliers. D’autres sont à la disposition du créateur de la chaine de traitement.
Ainsi, les résultats de géolocalisation seront placés dans une couche de données nommée « USER_1 » :

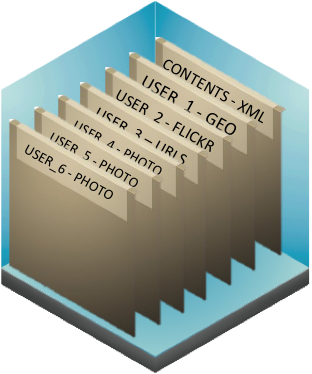
Dans notre exemple, nous allons ranger les résultats de la recherche d’images Flickr dans « USER_2 » et nous conserverons les liens vers les 3 premières photos dans « USER_3 » :
 →
→ 
Enfin, nous rangerons ensuite les photos elles-mêmes dans les couches « USER_4 » à « USER_6 » :
Utilisons Flickr via son API
Pour faire cela, de la même façon que l’on avait appelé le web service de Google Maps, appelons celui de Flickr en lui passant en paramètre la latitude et la longitude de chaque musée :
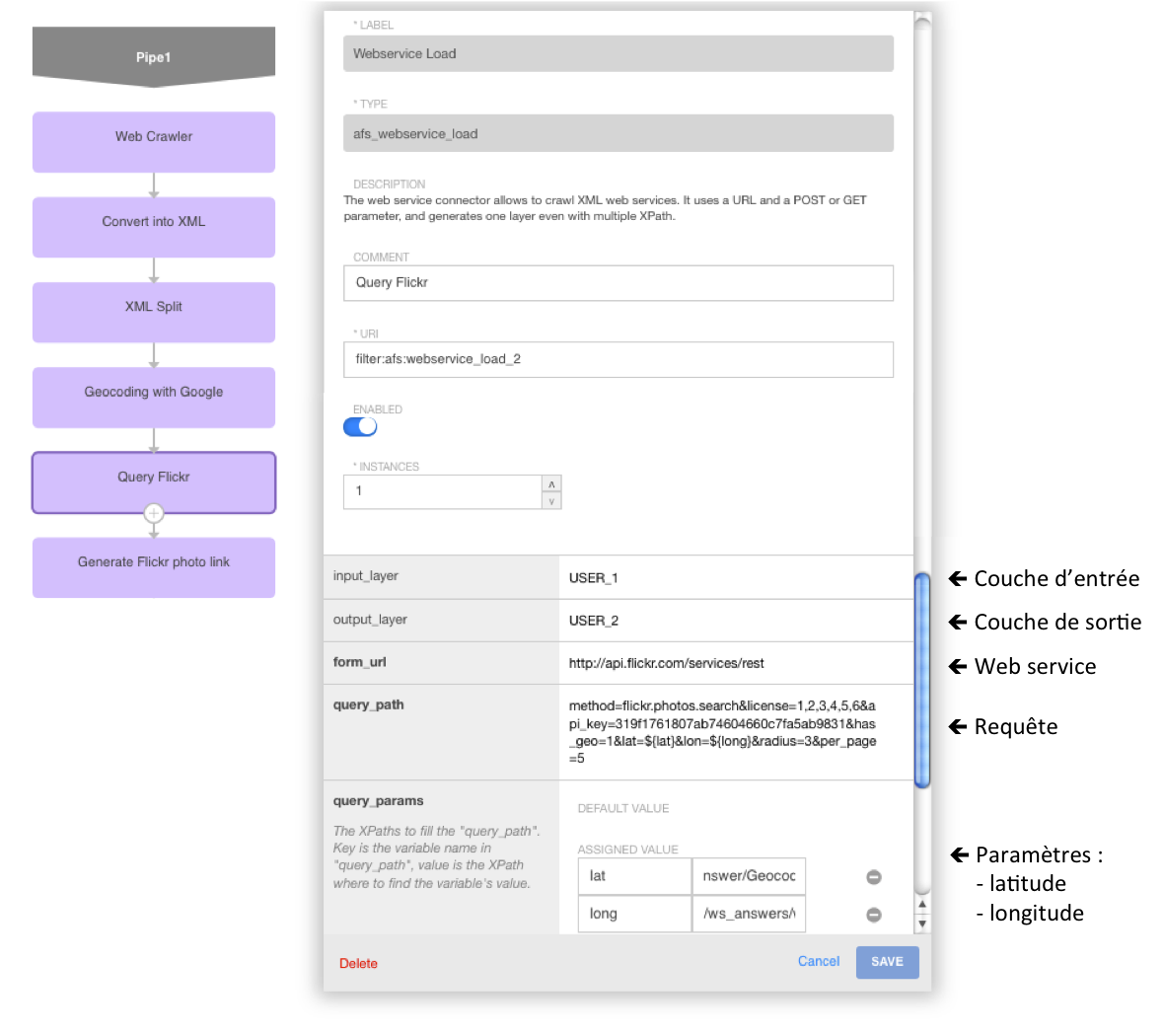
Nous récupérons alors le contenu des ces images, sous forme de fichiers au format JPEG, que nous stockons directement dans des couches de notre objet Musée. En effet, la solution Antidot Information Factory intègre un composant de stockage NoSQL appelé Content Repository. Grâce à lui, les photos seront directement accessibles via des web services pour toute application qui en aurait besoin. C’est ainsi que le widget d’affichage d’un objet musée sur l’application web pourra présenter les 3 photos.
Voilà, nos fiches présentant les musées sont désormais illustrés de photos !
Nous verrons dans le prochain billet comment indiquer, pour chaque musée, quelle sont les gares SNCF les plus proches…