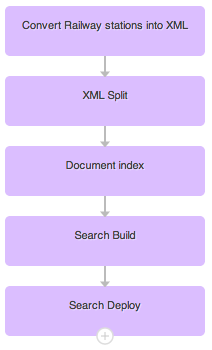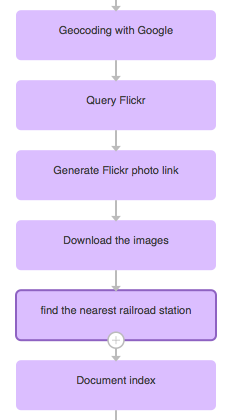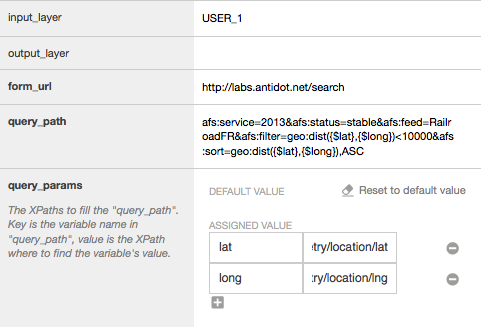
Dernier billet de notre série consacrée aux bonnes pratiques pour réduire au maximum les recherches sans réponse : nous allons voir qu’il est possible d’être moins strict dans les combinaisons de mots-clés et aussi de mettre en place des rebonds vers du contenu pertinent en cas de requête vraiment sans réponse.
3. Requête trop précise – Recherche optionnelle
Parfois, la requête ne donne pas de résultats parce qu’elle contient de nombreux mots-clés dont la combinaison contraint fortement les résultats.
Il est utile, dans ces cas là, de proposer une recherche optionnelle où tous les mots-clés ne sont pas obligatoires : le moteur de recherche utilise alors un opérateur OU au lieu de ET entre les différents mots de la requête. Le mécanisme de pertinence fait en sorte que les documents contenant le maximum de mots-clés parmi ceux cherchés soient proposés en priorité.
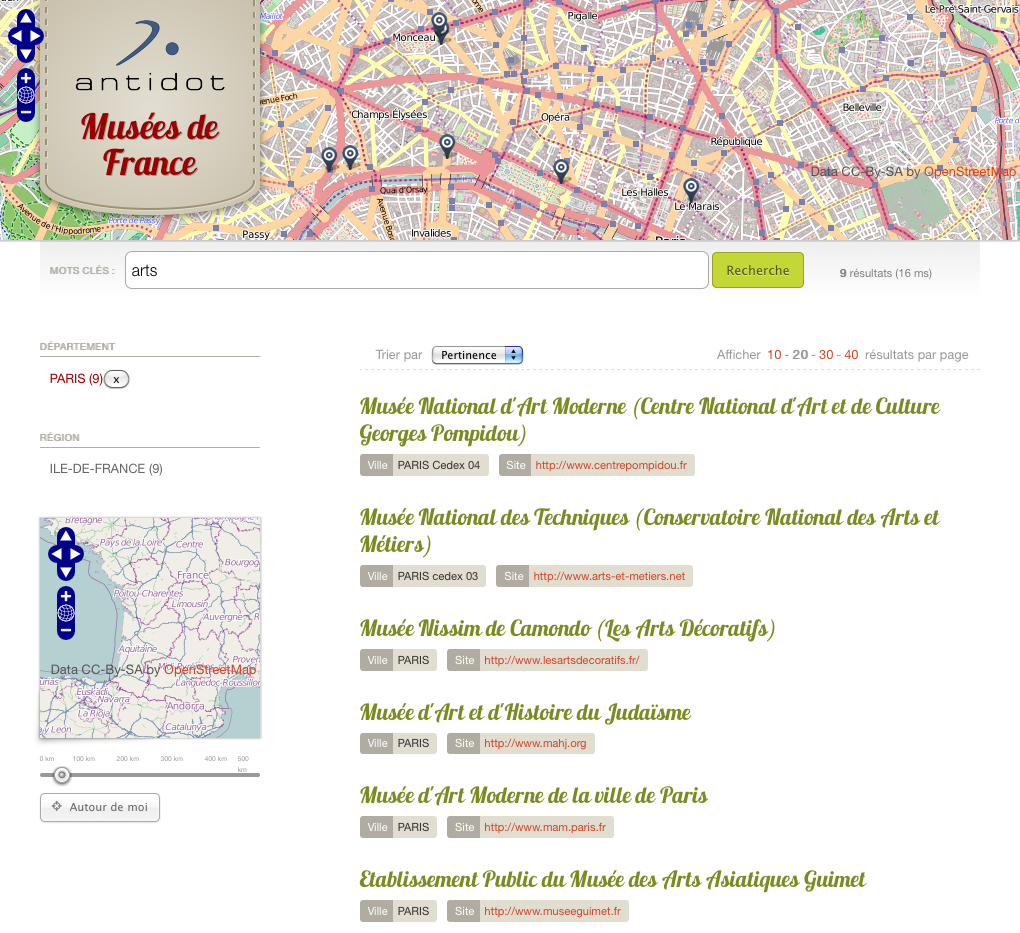
Le CSA propose un mode de recherche optionnel sur son site web. En l’absence de rapport 2014, la recherche «Rapport annuel 2014 » propose des rapports plus anciens.
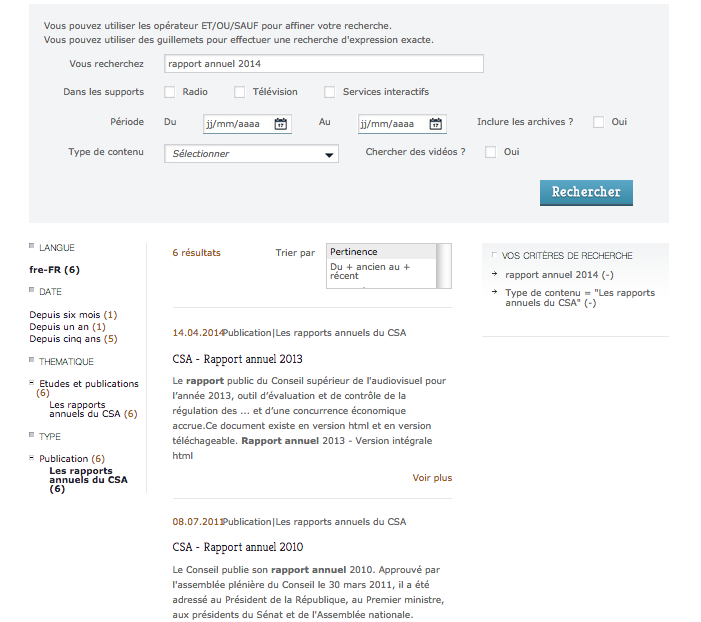 Cliquer pour agrandir l’image
Cliquer pour agrandir l’imageCompte tenu du bruit potentiel que la recherche optionnelle peut engendrer, il est tout de même recommandé de commencer par une requête classique et, en cas de non réponse seulement, d’exécuter une requête optionnelle en informant l’utilisateur du fait que l’on a élargi sa recherche.
4. Contenus non indexés
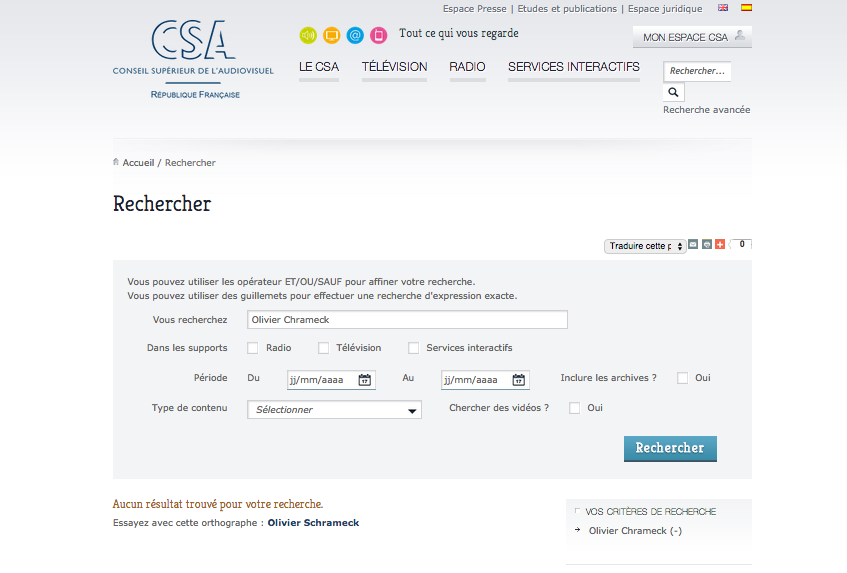
Parfois, vos utilisateurs cherchent des informations que vous n’avez pas indexées dans le moteur de recherche, comme par exemple l’adresse ou numéro de téléphone du service client.
Dans ce cas, il est utile de prévoir un comportement approprié du moteur de recherche qui pourra rediriger l’utilisateur vers la page concernée de votre site web. Il suffit pour cela d’intercepter un certain nombre de mots -clés pour gérer une redirection vers une page particulière, au lieu de laisser le moteur exécuter sa recherche.
Malheureusement dans certains cas, l’utilisateur cherche vraiment un contenu que vous n’avez pas. Pour autant, même dans ces cas là il ne faut pas négliger votre page de réponse.
Voici quelques éléments que vous pouvez fournir et qui peuvent aider l’utilisateur à rebondir vers d’autres contenus :
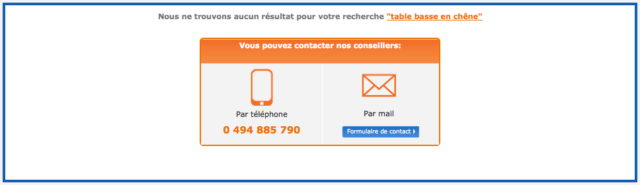
- Proposer l’aide d’un conseiller :
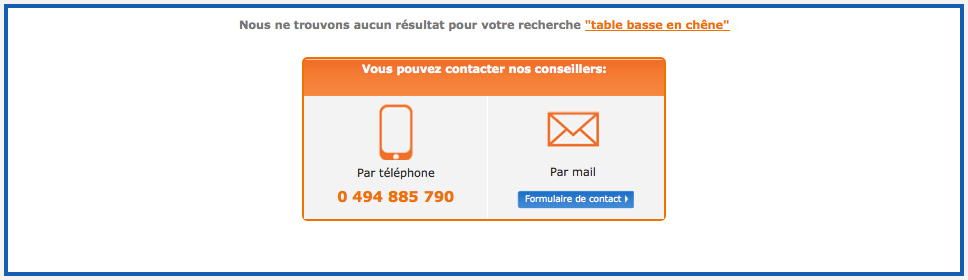 Cliquer pour agrandir l’image
Cliquer pour agrandir l’image - Proposer la liste des contenus les plus consultés
- Proposer un hit-parade des requêtes les plus fréquentes :
 Cliquer pour agrandir l’image
Cliquer pour agrandir l’image - Proposer une liste éditorialisée de contenus, par exemple les meilleures ventes pour un site marchand :
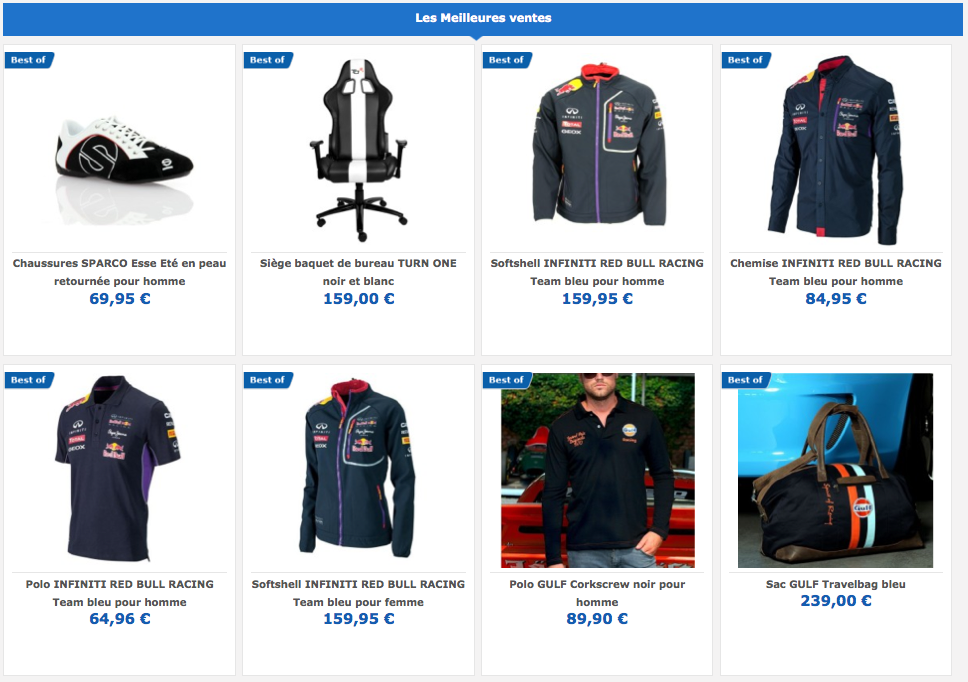 Cliquer pour agrandir l’image
Cliquer pour agrandir l’image
Les exemples ci-dessus proviennent du site Oreca Store, spécialisé dans le sport automobile et où, bien que le catalogue soit extrêmement riche, on ne trouve pas de « table basse en chêne » 😉
Dans tous les cas, améliorer la pertinence de votre moteur de recherche et optimiser ses réponses est un processus continu. Une analyse régulière de vos requêtes sans réponse vous permettra d’enrichir vos dictionnaires, d’identifier les cas qui posent régulièrement problème, et de mettre en place les fonctionnalités adéquates.
Il n’est pas nécessaire d’y passer beaucoup de temps, et cela paye vraiment : 10 minutes par semaine sont largement suffisants, et vous constaterez aussitôt une amélioration réelle !
N’hésitez pas à nous faire part, en commentaire, de vos propres astuces pour satisfaire au mieux les requêtes de vos clients, ou si vous avez déjà rencontré un cas d’usage non couvert dans ces billets !

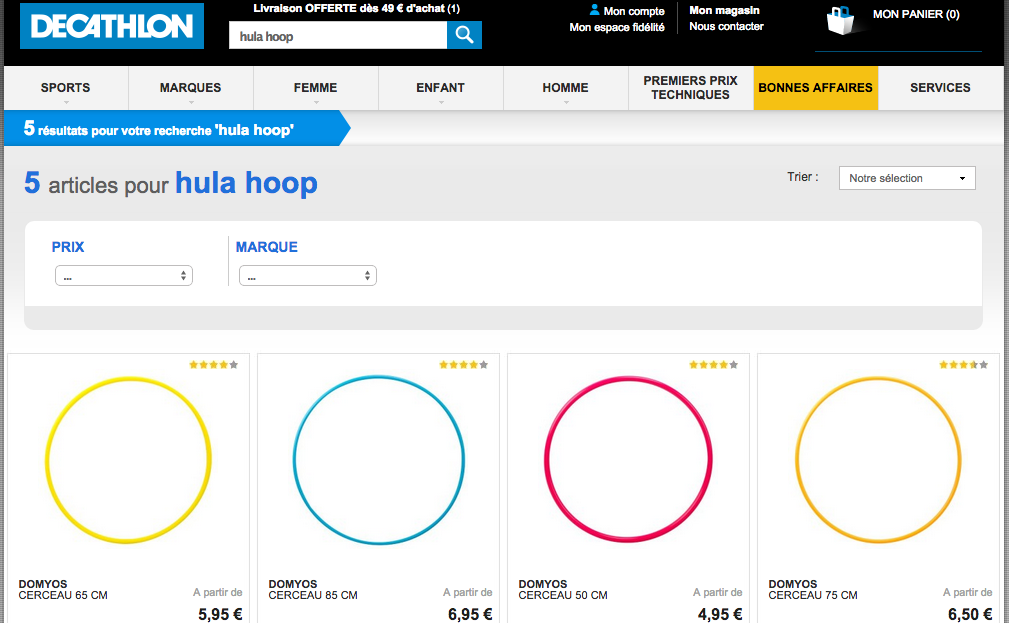 Cliquer pour agrandir l’image
Cliquer pour agrandir l’image Cliquer pour agrandir l’image
Cliquer pour agrandir l’image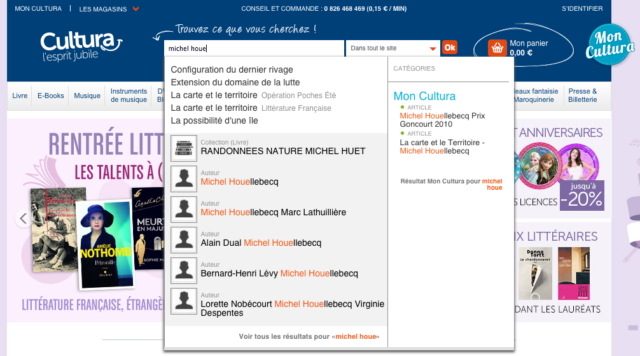
 Cliquer pour agrandir l’image
Cliquer pour agrandir l’image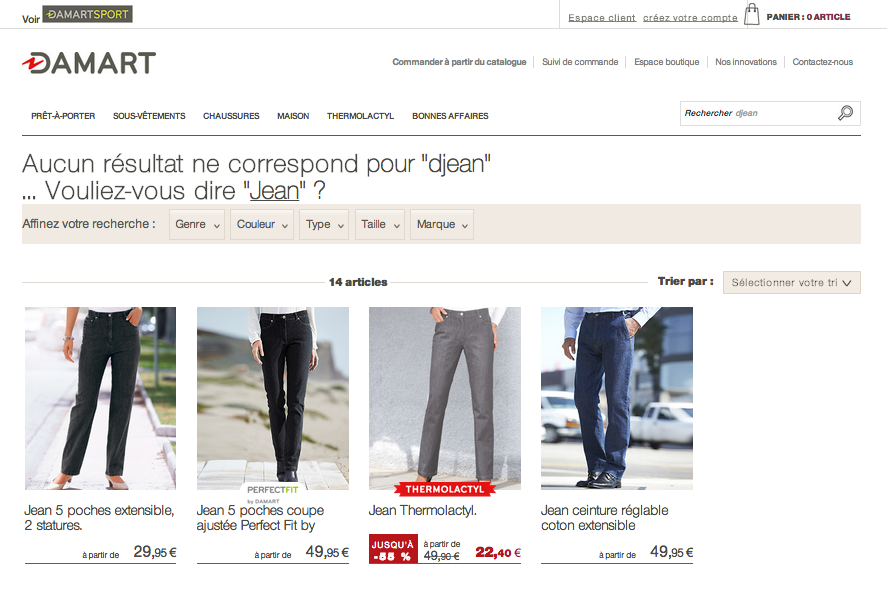 Cliquer pour agrandir l’image
Cliquer pour agrandir l’image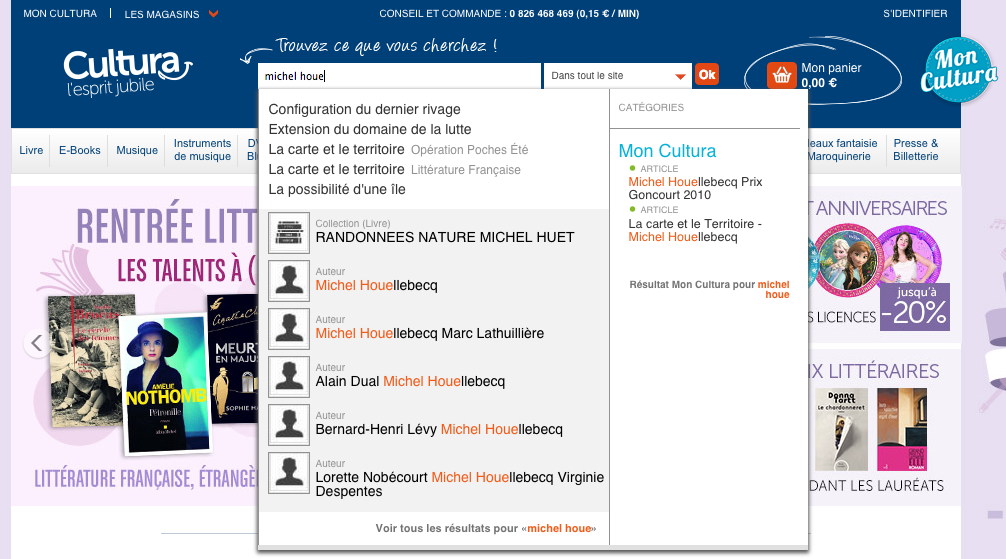 Cliquer pour agrandir l’image
Cliquer pour agrandir l’image