
Le terme DevOps est apparu il y’a environ une dizaine d’années et est largement utilisé dans de nombreuses fiches de poste (dont la mienne) mais il reste encore flou aujourd’hui. Je vais donc essayer de me lancer dans une définition ; ou du moins dans la définition que nous en faisons chez Antidot.
Origine du mot DevOps
 DevOps vient de la contraction de 2 termes anglais « development » « operation* ( *exploitation en français) ». Cela part du postulat qu’il y’a donc deux mondes, celui des développeurs donnant vie à un produit, et celui des administrateurs système qui l’opère dans le Datacenter.
DevOps vient de la contraction de 2 termes anglais « development » « operation* ( *exploitation en français) ». Cela part du postulat qu’il y’a donc deux mondes, celui des développeurs donnant vie à un produit, et celui des administrateurs système qui l’opère dans le Datacenter.
Avec l’apparition des méthodes agiles, ce postulat est mis à mal, et le terme DevOps fait son apparition en proposant le trait d’union entre ces deux mondes. Le « DevOps engineer » n’est plus un simple admin, mais s’oriente plus vers un développeur qui aurait pleinement conscience des ressources requises par son produit, et saurait comment l’opérer efficacement dans un espace de production car il en connaît toutes les ficelles. Cette double compétence permet une grande réactivité, et est un atout non négligeable dans un procès de déploiement continu ou d’intégration continue.
Et Antidot alors ?
Antidot est un éditeur logiciel spécialisé dans la transformation et l’enrichissement de données, aussi, la société propose plusieurs produits qui utilisent une architecture assez complexe. C’est là qu’une approche DevOps est intéressante, voir indispensable pour opérer un Datacenter en perpétuelle évolution.
En effet, le marché fait que nous avons régulièrement besoin d’ajouter/réinstaller de nombreuses machines. Amazon avec AWS fait ça très bien, mais nous préférons opérer nous-même 95% de notre Datacenter (5% étant quand même chez AWS). Nous voulons avoir la même souplesse qu’AWS en termes de mise à disposition de machines, pour cela nous utilisons divers outils qui nécessitent des compétences en développement comme Puppet (ruby)/Ansible (python)/FAI (bash) ou encore Docker et LXC pour la virtualisation. Aujourd’hui une installation complète d’une machine pour notre DC (comprendre avec compte UNIX, produit installé « Up & Running ») prend moins de 10 mins pour une machine bare-métal, moins de 5 minutes pour un container LXC et quelques secondes pour un container sous docker.
Même si cette partie utilise des compétences de DEV, elle reste très orientée, OPS. Ce n’est pas le seul besoin que nous avons chez Antidot, comme je l’évoquais un peu plus haut, nous avons besoin de réduire et d’automatiser au maximum le passage en production de chaque ligne de code* (*de chaque commit) produite par nos développeurs « de souche ». Il a fallu repenser toute la chaine de livraison/test de notre solution.

Ce besoin est résolu avec la mise en place d’une architecture basée sur les fonctionnalités offertes par docker et gitlabCI. Ainsi, un développeur peut à loisir développer dans une branche git sur son propre poste, chaque commit déclenche l’instanciation d’un environnement virtualisé complet à l’image de notre production, afin d’y effectuer une série de tests. Une fois tous les tests passés, le commit est automatiquement mergé/fusionné dans la branche principale de notre produit, et une nouvelle version est livrée, prête à être installé en production. A chaque étape, une notification est envoyée au développeur (dans une room Hipchat) lui permettant un retour « temps réel ». Il va de soi que le déploiement vers l’environnement de production est également automatisé, ce qui ne veut pas dire automatique. Nous préférons garder le contrôle sur le moment où nous déployons en un clic vers tout notre parc de production. A titre d’exemple, avant cette automatisation, une mise à jour de production pouvait prendre plus d’une journée à un de nos administrateur système pour tout le parc, elle a été réduite à 20 secondes pour appeler la commande et à 20/30 minutes pour son exécution (temps incompressible d’arrêt et de redémarrage des services sur tout notre parc de production).
Le monitoring en Devops
Le monitoring est egalement opéré en mode DevOps. Chez Antidot, nous utilisons principalement Shinken. Shinken utlise une liste de « hosts » et de « probes » statique. Avec notre Datacenter devenu dynamique, il a fallut ecrire une bibliotheque capable de découvrir tous les hosts provenant de notre inventaire (GLPI) et de leur appliquer les bonnes sondes metier en fonction de certain critères/tags. Grace a cette bibliotheque écrite en Python, nous pouvons par exemple ajouter une machine dans un cluster Mongo (Kickstart + playbook Ansible), le monitoring arrive automatiquement avec uniquement les psondes necessaire.
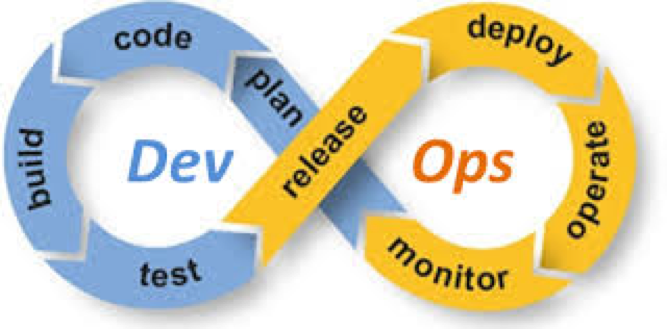
Le « devops » chez Antidot ne consiste pas à réinventer la roue, mais à utiliser une multitude d’outils/de standard open source (ou non), et de créer le « liant » entre tous ces outils afin de ne pas avoir à répéter deux fois une même action (là ce sont mes origines Corses qui parlent). D’aucun diront* (* les mauvaises langues) que c’est une sorte de fainéantise poussé à l’extrême, afin de simplifier ses tâches. Je préfère dire que c’est plus une façon de se débarrasser des tâches ingrates/répétitives en créant une architecture « vivante » et « dynamique », et surtout plus intéressante, piloté d’une main de maitre 🙂

C’est un défi que nous aimons relever et qui nous permet de nous tenir au fait des nouvelles technologies. A ce titre, si tu es comme nous et que tu souhaites faire de cette philosophie devops ton quotidien, je rappelle qu’Antidot recrute un Administrateur DevOps, n’hésite pas à nous contacter, toute proposition sera étudiée.
Article rédigé par Yann Finidori









 A l’origine initié par la société
A l’origine initié par la société  Le Ship It Day est avant tout une aventure humaine, ludique, faisant de l’évènement un vecteur d’émulation très fort. Cela permet de faire une pause dans le train-train quotidien, tout en avançant rapidement sur des projets, au final relativement aboutis.
Le Ship It Day est avant tout une aventure humaine, ludique, faisant de l’évènement un vecteur d’émulation très fort. Cela permet de faire une pause dans le train-train quotidien, tout en avançant rapidement sur des projets, au final relativement aboutis. Après cette première édition fin mars, la prochaine est prévue les 18 et 19 juin prochains. Au total, ce seront donc quatre Ship It Day qui seront organisés par an, au rythme d’un par trimestre.
Après cette première édition fin mars, la prochaine est prévue les 18 et 19 juin prochains. Au total, ce seront donc quatre Ship It Day qui seront organisés par an, au rythme d’un par trimestre.


 Source : wikibook «
Source : wikibook « 





