
Nous avons vu dans un précédent billet comment traiter automatiquement les erreurs de saisie et fautes de frappe.
Examinons maintenant un autre cas de figure :
2. Les requêtes utilisant un vocabulaire différent du vôtre
Dans ce cas l’utilisateur ne s’est pas trompé dans sa requête, mais a utilisé un vocabulaire qui n’est pas celui de vos documents ou fiches produits. Plusieurs scenarii sont possibles :
a. L’utilisation de synonymes ou abréviations
Les utilisateurs peuvent utiliser des mots différents de ceux de vos fiches, pourtant ils désignent la même chose : « gratte » au lieu de « guitare » pour un musicien de rock, « voiture » ou même « bagnole » pour « automobile », « loi Aubry » ou « loi des 35 heures » pour « loi n° 98-461 ».
Une solution basique serait de surcharger manuellement vos documents avec les différentes formes possibles des mots utilisés : cela fonctionnerait, mais c’est loin d’être la solution optimale.
Utilisez plutôt un dictionnaire de synonymes. Démarrez avec une simple liste à plat de mots ou d’expressions et listez les synonymes métier, les abréviations fréquemment employées… Ces équivalences seront appliquées automatiquement par le moteur de recherche pour optimiser la réponse à vos utilisateurs.
Chez Decathlon le terme « hula-hoop » désigne aussi un « cerceau » :
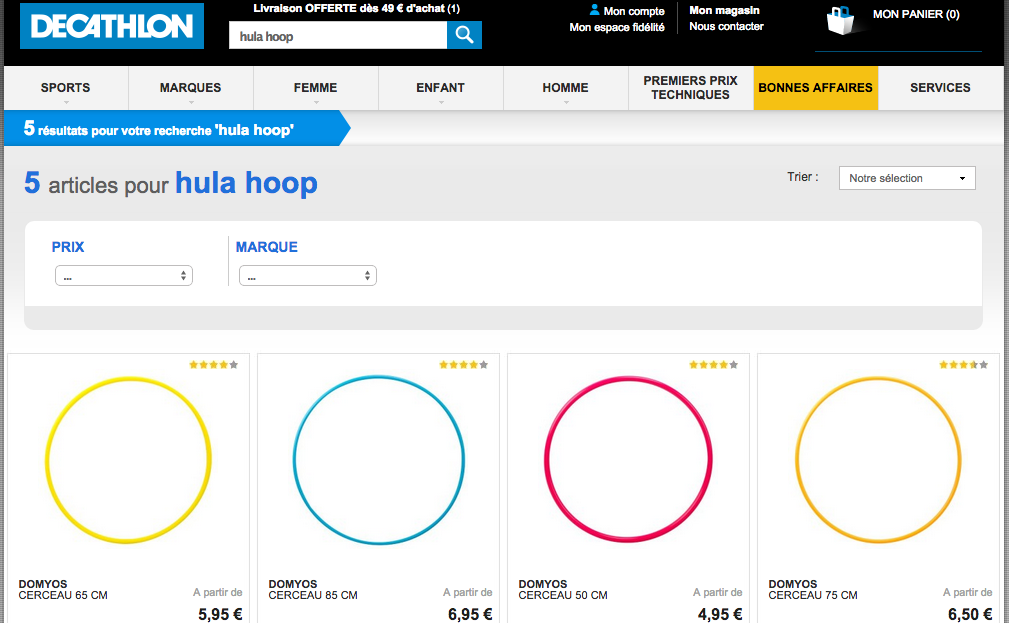 Cliquer pour agrandir l’image
Cliquer pour agrandir l’imageVous n’avez pas besoin de constituer la liste d’une seule traite, commencez par une première base, que vous enrichirez au fur et à mesure.
b. L’utilisation de concepts parents
Vos utilisateurs peuvent parfois utiliser des termes plus larges que ceux très spécifiques utilisés dans vos contenus. Mais on ne peut pas parler de synonymes au sens strict. Un utilisateur peut par exemple chercher « voiture » là où vos documents mentionnent des « cabriolets », ou encore chercher « sport de raquette » quand vos documents évoquent spécifiquement le « tennis », le « badminton » ou le « ping pong ».
Dans ce cas là, il est préférable de passer par un dictionnaire de concepts hiérarchisé, ou thesaurus.
A la différence de la liste de synonymes mentionnée plus haut, le thesaurus sert à organiser des termes de manière hiérarchique avec plusieurs niveaux d’information. On parle dans ce cas de concepts parents ou enfants.
Les moteurs de recherche utilisent ces dictionnaires pour répondre de manière précise à des requêtes larges ou floues, mais en aucun cas ils ne doivent répondre de manière générique à une requête très précise : il faut en effet prendre comme hypothèse que l’utilisateur qui cherche un terme très précis souhaite justement obtenir un contenu adapté.
Sur le site « Croquons la vie » de Nestlé, les « snacks » désignent les « burgers » , « tartines » et « croque-monsieur » :
 Cliquer pour agrandir l’image
Cliquer pour agrandir l’imageLes moteurs de recherche de dernière génération savent prendre en compte les niveaux de hiérarchie dans le classement par pertinence de leurs résultats.
Ainsi un moteur de recherche efficace, comme Antidot Finder Suite, va d’abord proposer des fiches qui contiennent exactement le mot recherché avant de proposer d’autres fiches qui contiennent des concepts enfants.
c. Compréhension du langage naturel
Dans d’autres cas les utilisateurs vont, en plus des mots clés significatifs, utiliser des expressions pour mieux qualifier leurs requêtes : « Inférieur à un certain prix », « Postérieur à une certaine date »… et se retrouvent sans réponse alors que avez du contenu adapté.
Prenons l’exemple suivant d’un site de e-commerce: si un visiteur saisit « Chaussures à moins de 100 euros« , cette requête risque de ne pas donner de résultats parce qu’il n’y a probablement pas de fiches de chaussures contenant « à moins de ». Et elle ne proposera pas des chaussures à 50 euros, parce que leur fiche ne contient pas « 100 ».
Il est facile pour nous humains, dotés d’un cerveau très puissant, d’interpréter la recherche et de se rendre compte qu’en fait la recherche porte simplement sur des chaussures, avec un filtre sur leur prix. Mais c’est bien plus compliqué lorsqu’il s’agit de l’expliquer au moteur de recherche !
Il existe donc, pour gérer ce genre de cas, des modules de réécriture qui servent à identifier certaines formes de requêtes et à les transmettre au moteur de recherche avec la syntaxe qu’il sait gérer au mieux.
Dans notre cas, l’expression « à moins de 100 euros » se retrouve réécrite en filtre : « prix < 100 », permettant ainsi au moteur de trouver les résultats pertinents.
d. Information existante mais pas sous forme de mots-clés
Dans certains cas, l’information recherchée est présente dans vos contenus, mais pas sous forme de plein texte.
Dans un catalogue de produits alimentaires par exemple, des clients peuvent rechercher le mot-clé « bio ». Mais si l’information n’existe que sous forme de case à cocher Oui / Non dans le catalogue, le moteur ne va pas retrouver le mot-clé en tant que tel dans les fiches des produits.
Le client n’aura donc pas de résultats alors qu’il existe de nombreux produits susceptibles de l’intéresser.
Dans ce cas, un traitement est à prévoir en amont. Il faut prévoir des mécanismes d’enrichissement de vos contenus qui ajoutent les mots-clés nécessaires à vos fiches avant leur indexation. Ces traitements peuvent directement être pris en charge par le moteur de recherche.
Nous verrons la semaine prochaine comment traiter les cas de requêtes sans réponse qui subsisteraient encore après mise en oeuvre des bonnes pratiques que nous vous avons présentées.
 Cliquer pour agrandir l’image
Cliquer pour agrandir l’image Cliquer pour agrandir l’image
Cliquer pour agrandir l’image Cliquer pour agrandir l’image
Cliquer pour agrandir l’image







