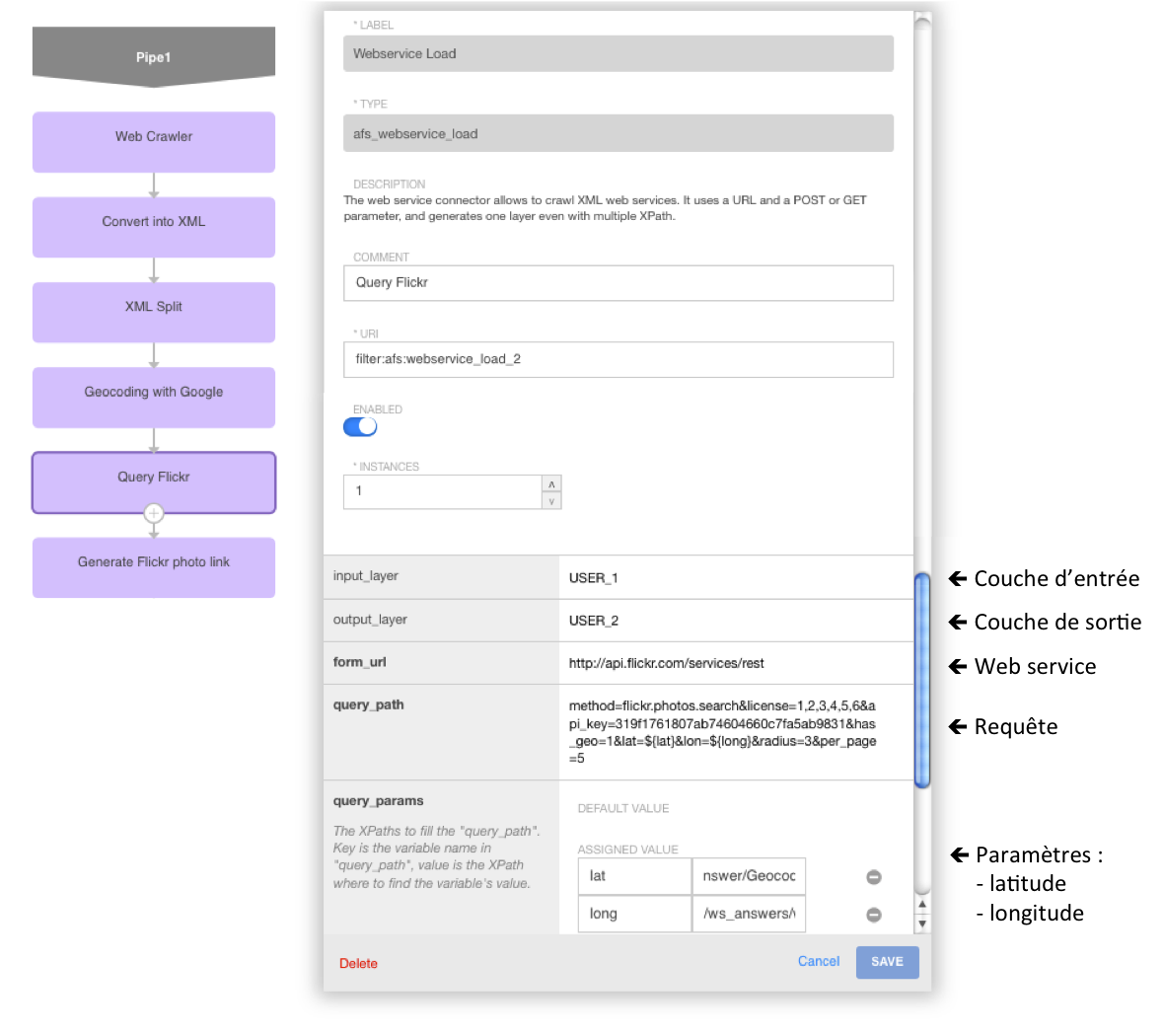
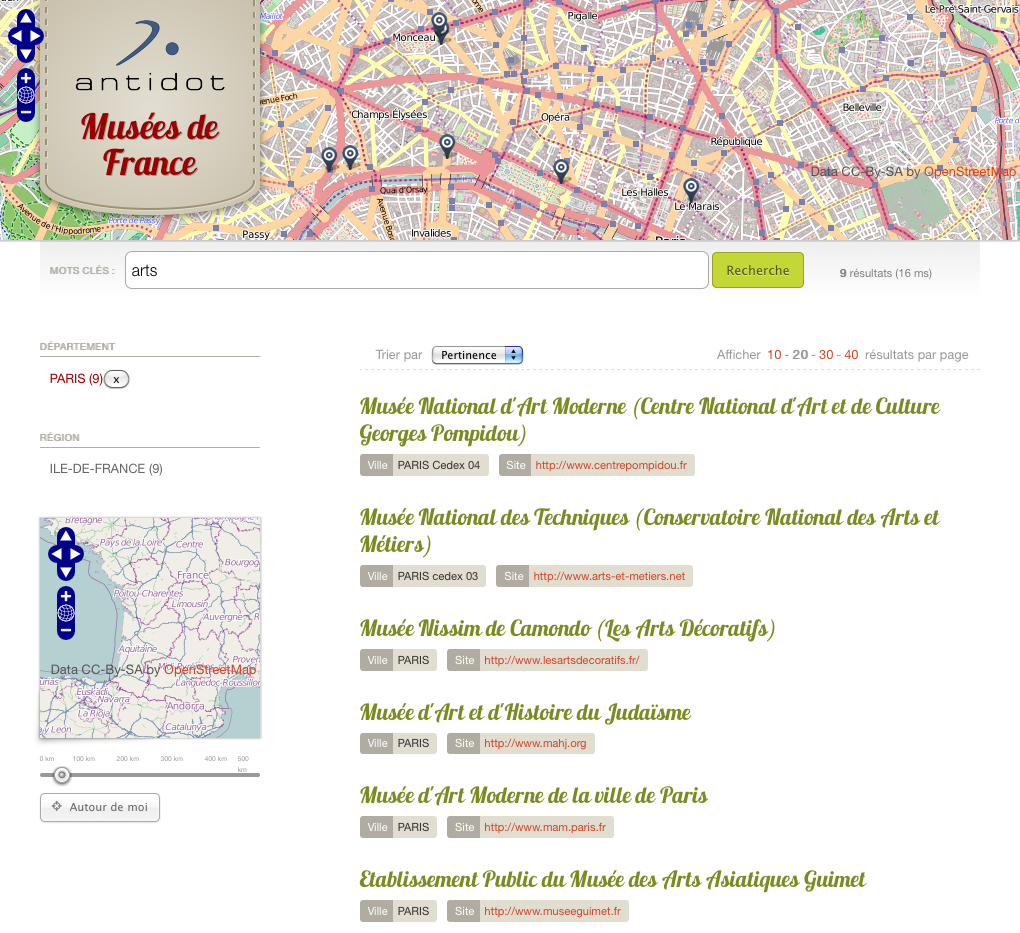
Dans un précédent billet, nous avons exposé notre perception des enjeux stratégiques pour data.gouv.fr, en réponse à la consultation Etalab : confiance dans les données et intégration dans l’écosystème du web.
Dans un précédent billet, nous avons exposé notre perception des enjeux stratégiques pour data.gouv.fr, en réponse à la consultation Etalab : confiance dans les données et intégration dans l’écosystème du web.
Ces enjeux trouvent leur réponse dans des choix organisationnels et technologiques :
- Comment améliorer la collecte et la pertinence des données ?
- Comment faciliter la réutilisation et l’exploitation des données ?
« Comment améliorer la collecte et la pertinence des données ? »
Crowdsourcing et aspects collaboratifs
Le « crowdsourcing » est en vogue, mais les coûts de mise en place de l’infrastructure nécessaire au travail collaboratif et d’animation d’une communauté nous semblent bien supérieurs aux retours réels. Il nous paraît plus intéressant de mettre en place des actions communes avec des communautés bien établies comme par exemple, Wikipedia, Open Street Map et ainsi de profiter de leur savoir-faire et de leur infrastructure dans l’animation d’une communauté.
À titre d’exemple, il serait intéressant de s’appuyer sur le portail DataHub administré par l’Open Knowledge Foundation pour repérer de nouveaux jeux de données disponibles relatifs à la France, et aussi mieux faire connaître les jeux de données publiés sur Etalab.
Automatisation de la collecte et des traitements
Jusqu’à maintenant, le portail data.gouv.fr s’est limité à la mise à disposition des jeux de données sans retraitement, tels qu’ils ont été chargés au sein du portail par les producteurs et à leur description via quelques métadonnées.
Il nous paraît envisageable de déployer une infrastructure technique à même d’effectuer des tâches automatiques pour collecter, nettoyer, harmoniser et relier les jeux de données disponibles sur le portail. Ce travail pourrait se situer aussi bien au niveau des métadonnées des jeux de données que des données elles-mêmes. C’est exactement ce qu’a réalisée le CNRS dans le cadre du projet ISIDORE.
« Comment faciliter la réutilisation et l’exploitation des données ? »
Se donner l’objectif d’un portail de données « 5 étoiles »
Dans le document « Publishing Open Government Data » publié en 2009 par le W3C, Daniel Bennett et Adam Harvey ont expliqué les différentes étapes pour publier des données « gouvernementales ». Ils insistent sur le fait de rendre les données accessibles aussi bien pour les humains que pour les machines et reprennent les éléments exposés par Sir Tim Berners-Lee, l’inventeur du Web, dans sa typologie des initiatives de mise à disposition libre des données sur le Web.
Aujourd’hui data.gouv.fr n’en est qu’à la première étape, c’est-à-dire « la mise à disposition sur le Web quel que soit le format mais avec une licence libre ». Or nous sommes convaincus que la réutilisation massive des données n’est possible à terme que si les jeux de données s’intègrent parfaitement dans le Web, en utilisant ses principes et standards.
 Dans un premier temps, il est nécessaire et urgent de proposer un annuaire des jeux de données disponibles dans un langage machine (XML, Json ou CSV) et de préférence en suivant les principes et standards du Linked Data (ou Web de données) basés sur des URI pour identifier les ressources, le protocole HTTP pour y accéder, les standards RDF pour récupérer une information sémantisée et le maillage systématique des données pour créer un écosystème basé sur les liens. Pour cela, Etalab pourrait utiliser le vocabulaire DCAT (Data Catalog Vocabulary) en cours de normalisation au sein du W3C par le groupe de travail « Government Linked Data ».
Dans un premier temps, il est nécessaire et urgent de proposer un annuaire des jeux de données disponibles dans un langage machine (XML, Json ou CSV) et de préférence en suivant les principes et standards du Linked Data (ou Web de données) basés sur des URI pour identifier les ressources, le protocole HTTP pour y accéder, les standards RDF pour récupérer une information sémantisée et le maillage systématique des données pour créer un écosystème basé sur les liens. Pour cela, Etalab pourrait utiliser le vocabulaire DCAT (Data Catalog Vocabulary) en cours de normalisation au sein du W3C par le groupe de travail « Government Linked Data ».
Dans un second temps, il serait important, comme le fait le portail britannique data.gov.uk, d’appliquer ces principes à certains jeux de données : la conversion en RDF de certains jeux de données de data.gouv.fr permettrait de proposer leur interrogation via un SPARQL endpoint constituant un Web service universel pour l’interrogation des données structurées et favorisant la réutilisation.
Poser une exigence de qualité des données et de complétude des métadonnées
Assurer la confiance sur le long terme passe par une exigence de qualité sur les données comme sur les métadonnées qui les décrivent. A cet égard, nous avons fait une amère expérience sur la version actuelle de data.gouv.fr.
Les données sont issues de processus et de traitements informatiques qui peuvent évoluer, donc les structures de données peuvent changer. C’est pourquoi le portail data.gouv.fr devrait inclure un système de gestion des versions et documenter les changements, au niveau de la fiche sous la forme d’un « changelog » et aussi dans les métadonnées. Ces changements seront disponibles dans un langage machine pour être interprétables par les logiciels consommateurs des données.
D’une manière générale, il nous semble que des métadonnées sont nécessaires pour disposer d’un contexte suffisant pour apporter la confiance, et notamment la provenance du jeu de données, le nom du producteur, la date de création, la date de mise à jour, la périodicité de mise à jour, la portée géographique des données, la portée temporelle des données.
Proposer des APIs pour simplifier la réutilisation
Comme l’a montré Christian Fauré dans son billet « DataCulture et APIculture », les principes du Linked Data et la mise en place d’Open API sont complémentaires et répondent à des usages différents : si les API, plus proches des pratiques actuelles des développeurs, simplifient la réutilisation des données et favorisent leur inclusion dans une économie marchande, les technologies du Web sémantique et les principes du Linked Data inscrivent directement les données dans l’espace d’interopérabilité global que constitue le Web.
Autres sujets, non technologiques, abordés dans notre réponse à Etalab
Le questionnaire établi par Etalab comportait d’autres points, relatifs à l’utilisation du portail et à sa visibilité :
« Quelle doit être l’expérience utilisateur sur le site ? »
Nous avons proposé d’améliorer la navigation pour favoriser la sérendipité, et suggéré des pistes pour mieux faire connaître les jeux de données et mieux accompagner les institutions publiques dans le monde de l’Open Data
« Comment favoriser la réutilisation et l’innovation à partir de la plateforme ? »
Une des difficultés de l’Open Data réside paradoxalement dans les vastes perspectives qu’il offre : il est complexe d’imaginer de nouveaux usages à partir de données brutes dont le contexte de création est inconnu. Il faut donc accompagner à la fois les développeurs, mais pas seulement : les résultats des concours d’applications et des hackathons restent dans une sphère relativement restreinte. Il est donc nécessaire d’effectuer un véritable travail de marketing et de valorisation des différents jeux de données et des perspectives qu’ils ouvrent dans les différents secteurs de l’économie réelle.
Par exemple, sur la base de projets auxquels Antidot travaille
- dans le domaine des médias et de la presse, les données de l’Open Data permettent d’offrir des services contextuels aux contenus éditoriaux.
- dans le domaine des transports, la question de la « smart mobility » pour offrir informations pratiques et proposer des activités sur le lieu de destination est au cœur des enjeux.
Il faut ainsi susciter chez les acteurs économiques dans les différents secteurs d’activités des nouvelles perspectives, où l’utilisation des données ouvertes apparaît clairement comme créatrice de valeur.
« Comment mieux insérer data.gouv.fr dans le réseau des ressources open data »
Nous suggérons que Data.gouv.fr alimente au nom de la France le portail DataHub du Comprehensive Knowledge Archive Network pour inscrire l’action Open Data de la France dans une dimension internationale.
« Comment construire un retour vers les administrations qui partagent leurs données ? »
Il nous semble important que les administrations trouvent un intérêt à la mise à disposition de leurs données pour en comprendre l’enjeu. Or les organisations publiques sont productrices de données et aussi consommatrices : par la récupération de leurs propres données, lorsqu’elles ont été corrigées ou enrichies, et par l’utilisation des données issues d’autres organisations
Ainsi, une boucle de rétroaction positive peut se mettre en place pour
- améliorer au fur et à mesure la qualité des données mises à disposition
- mieux intégrer la démarche de mise à disposition libre des données au sein des systèmes d’information.
La plateforme Isidore a été construite sur ce modèle vertueux : cette expérience positive démontre qu’un important travail d’accompagnement est nécessaire, mais que ces efforts portent leurs fruits.
Conclusion provisoire
En complément de la synthèse que vous venez de lire, vous trouverez notre réponse complète sur notre site web, sous forme d’un document PDF disponible ici.
Nous espérons, par ce travail, avoir contribué utilement au développement de l’Open Data en France. N’hésitez pas à utiliser les commentaires de ce billet pour prolonger la réflexion en partageant votre point de vue !


 →
→